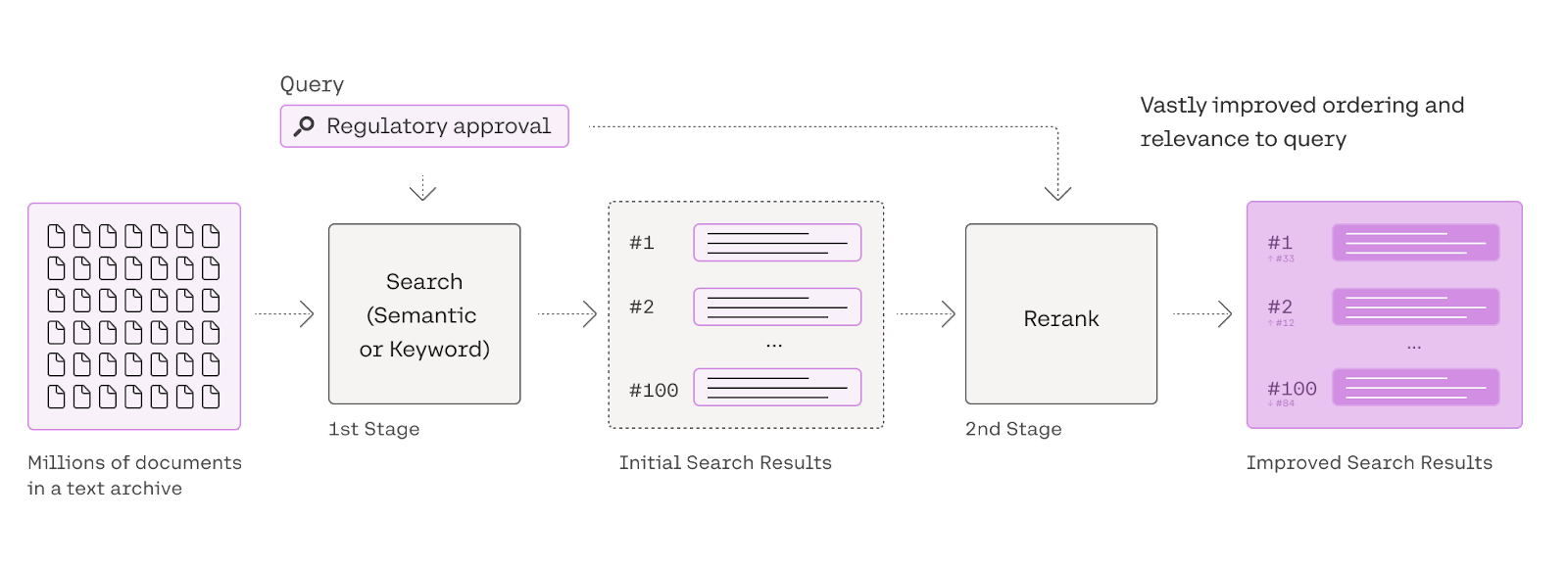
在資訊檢索(IR)系統的演進中,重排序算法(ReRank)的引入標誌著對搜尋結果質量控制的一大進步。特別是在 Retrieval Augmented Generation (RAG) 系統中,ReRank 的應用不僅提升了檢索結果的相關性,也為處理複雜查詢提供了更精細的操控手段。本節將深入探討重排序算法在 RAG 系統中的關鍵角色,並揭示其背後的運作原理與實踐意義。
本文大綱
重排序算法在資訊檢索系統中的核心作用
重排序算法(ReRank)在資訊檢索系統中扮演著不可或缺的角色,特別是在處理大規模文檔集合時。其主要工作流程是在初步檢索後,對文檔集合進行二次篩選和排序,目的是根據查詢和文檔之間的相關性,對文檔進行重新排列,從而提升檢索結果的質量和準確性。
提升檢索結果準確性
傳統的檢索系統往往依賴於向量空間模型(如 TF-IDF)或基於內積的相似度計算,這些方法雖然在大部分情況下能夠提供合理的檢索結果,但在處理語義上複雜或相關性微妙的查詢時,可能無法精細區分文檔的相關度。ReRank 通過引入更複雜的相關性判斷機制,如基於深度學習的模型,能夠更準確地識別查詢與文檔之間的相關性,從而有效提升檢索結果的準確性。
解決「幻覺」問題
在生成回答或提供搜尋結果時,「幻覺」現象(即檢索到的文檔與查詢無關)是一個常見問題,尤其是當檢索系統試圖處理開放式問題或非常具體的查詢時。ReRank 算法透過重新排序文檔來優先考慮最相關的內容,有效地解決了「幻覺」問題,進而提升了用戶對檢索結果的滿意度。
與 RAG 系統的結合
RAG 系統結合了資訊檢索和生成模型的優勢,以提供更加精確和豐富的回答。在這一過程中,ReRank 算法的作用尤為關鍵。通過對初步檢索到的文檔進行重排序,ReRank 確保了輸入生成模型的文檔是與查詢最相關的,從而大大提高了生成答案的質量和相關性。

在實踐中,選擇和優化重排序算法對於提升 RAG 系統的整體性能至關重要。不同類型的 ReRank 算法,如 Cross-Encoders、Multi-Vector Rerankers 或基於大型語言模型(LLM)的 ReRank 算法,各有其獨特的優勢和適用場景。因此,理解各種 ReRank 算法的特點和限制,並根據特定的應用需求進行選擇和調整,是實現高效、高質量 RAG 系統的關鍵。
重排序算法的工作原理與類型
重排序算法(ReRank)是資訊檢索(IR)系統中的關鍵技術,尤其是在 RAG(Retrieval Augmented Generation)系統中。它們的主要任務是在初步檢索結果的基礎上,透過更進階的算法進行二次排序,以提高檢索結果的相關性和準確性。本節將介紹重排序算法的工作原理與常見的類型,並探討它們如何在 RAG 系統中發揮作用。
重排序算法的工作原理
重排序算法的核心工作原理是基於查詢和文檔之間的相關性,重新排序初步檢索結果。這一過程通常涉及更複雜的相關性評估方法,遠超傳統的向量空間模型或內積相似度計算。重排序算法利用深度學習模型,如 BERT 或其他 Transformer 架構,來進行更細緻的語義理解和匹配。
語義關鍵字匹配
重排序算法中的一個關鍵技術是語義關鍵字匹配,它允許算法理解查詢和文檔中的關鍵詞之間的語義相關性。這種匹配方式超越了簡單的字面匹配,能夠識別同義詞和相關詞,從而提高檢索結果的準確性和相關性。
泛化能力的提升
通過對查詢和文檔進行更細粒度的分析,重排序算法能夠更好地處理未見過的查詢或文檔。這種細粒度的理解和泛化能力的提升,是通過將文檔和查詢拆分為更小的信息單位並利用強大的編碼器模型來實現的,這使得算法能夠捕捉到更深層次的語義關係。
重排序算法的類型
在 RAG 系統中,根據不同的需求和應用場景,可以選擇不同類型的重排序算法。以下是一些常見的重排序算法類型:
跨編碼器(Cross-Encoders)
跨編碼器是一種強大的重排序算法,能夠對每一對查詢和文檔進行詳細的相關性評估。這種方法雖然計算成本較高,但能夠提供非常精準的重排序結果,特別適合於對準確性要求非常高的應用場景。
多向量重排序器(Multi-Vector Rerankers)
多向量重排序器將文檔和查詢表示為多個向量,透過向量之間的互動來評估相關性。這種方法相較於跨編碼器在計算上更為高效,適合於需要處理大量文檔的場景。
| 重排序算法類型 | 特點 | 適用場景 |
|---|---|---|
| 跨編碼器(Cross-Encoders) | 高準確度的相關性評估 | 對準確性要求高的應用 |
| 多向量重排序器 | 較高的效率和可擴展性 | 大規模文檔處理、需要快速響應的場景 |

綜合上述,重排序算法透過對查詢和文檔之間相關性的深入分析和評估,顯著提升了 RAG 系統的檢索結果質量。選擇合適的重排序算法對於達成特定的系統性能和效率目標至關重要。隨著深度學習技術的進一步發展,我們可以預見重排序算法在未來將繼續對資訊檢索系統,特別是 RAG 系統,產生深遠的影響。
在當今進步飛速的資訊時代,隨著數據量的爆炸性增長,資訊檢索系統(IR)面臨著前所未有的挑戰。特別是在 Retrieval Augmented Generation (RAG) 系統中,如何從大量的數據中檢索出最相關的信息,成為了提升系統性能的關鍵。這其中,重排序算法(ReRank)扮演著至關重要的角色。本文將深入探討如何根據不同需求選擇合適的重排序算法,以及這些算法如何對 RAG 系統的效能產生影響。
重排序算法的選擇要點
選擇合適的重排序算法對於優化 RAG 系統至關重要。以下幾個要點是在選擇過程中需要考慮的:
- 相關性提升:重排序算法的首要目的是提高檢索結果與查詢之間的相關性。算法應能有效識別與查詢最為相關的文檔,並將它們排在檢索結果的前列。
- 延遲考量:儘管重排序算法能提高檢索結果的質量,但它也可能引入額外的延遲。因此,在選擇算法時,需要平衡相關性提升與系統響應時間之間的關係。
- 處理能力:不同的重排序算法在處理長短文檔、不同類型的查詢上可能有所差異。選擇過程中要考慮算法對不同長度上下文和複雜查詢的處理能力。
- 泛化能力:良好的重排序算法應具備強大的泛化能力,能夠適應不同領域和未見過的查詢,確保檢索結果的準確性和可靠性。

最新研究成果與未來展望
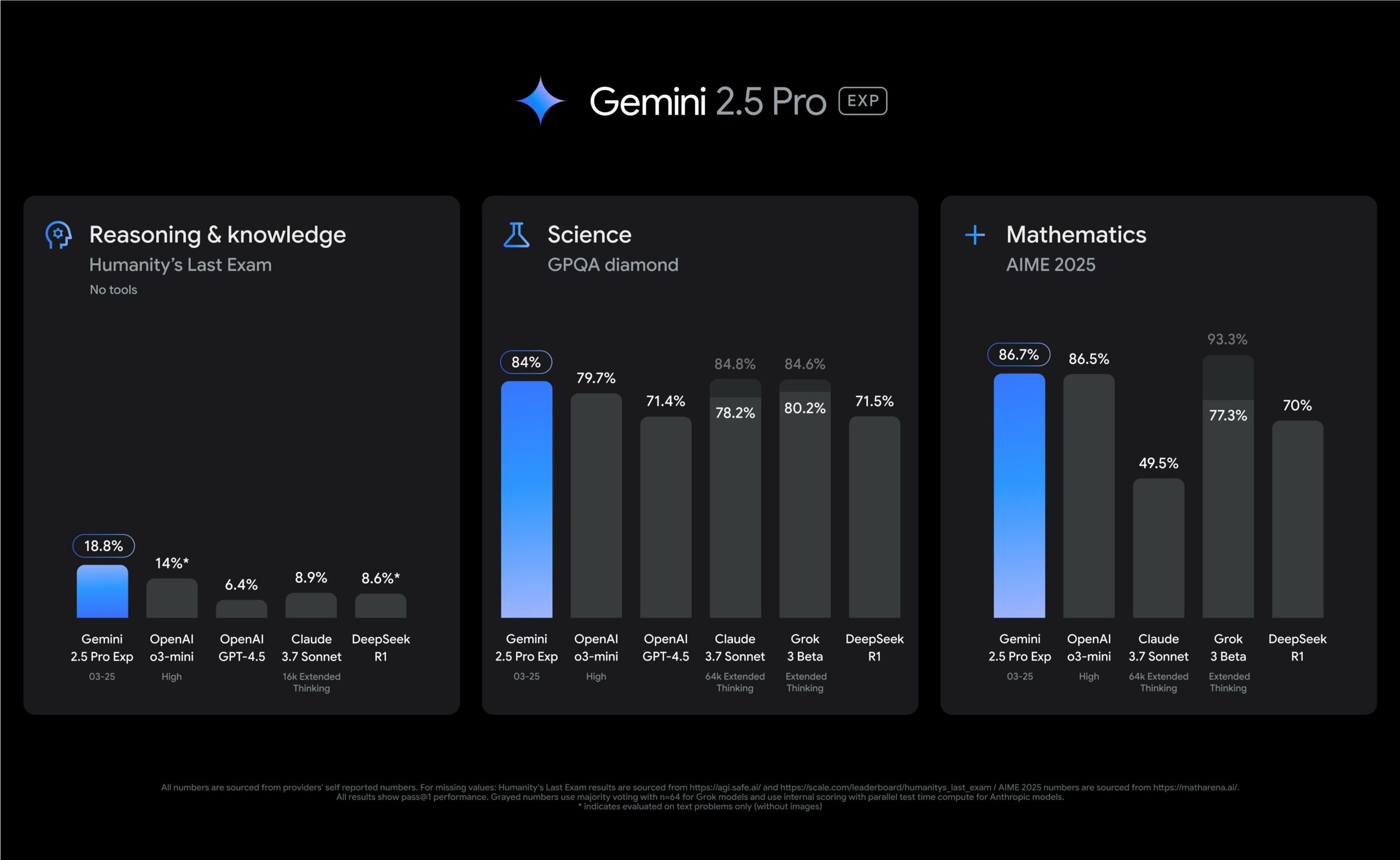
隨著人工智慧和機器學習技術的不斷進步,重排序算法也在不斷發展和完善。最新的研究成果表明,結合強大的檢索器,如基於 Transformer 的模型,可以顯著提升重排序算法的效能和效率。未來,隨著預訓練語言模型和深度學習技術的進一步發展,我們可以預見重排序算法在提高 RAG 系統效能方面將發揮更加關鍵的作用。

綜上所述,重排序算法在資訊檢索系統中的作用不可小覷。選擇合適的重排序算法是實現高效、高質量 RAG 系統的關鍵一步。通過對不同算法的特點、優勢和適用場景進行深入分析和比較,可以為系統的優化提供明確的指導,從而在滿足用戶需求的同時,實現資訊檢索系統的性能提升。隨著技術的不斷進步,重排序算法將繼續在資訊檢索領域發揮其不可替代的作用。
重排序算法(ReRank)在優化 RAG 系統和確保可靠搜尋結果中扮演著關鍵角色,特別是在增強搜尋精確性方面。隨著技術的進步和應用的深入,重排序算法的重要性日益凸顯。然而,隨著 RAG 管道的成熟,調試複雜性可能會妨礙系統的改進。在本篇文章的結尾,我們將總結重排序算法的關鍵作用並提供行動呼籲,鼓勵讀者深入探索不同的重排序算法,為 RAG 系統選擇最適合自己需求的算法,以提升系統的效能。
行動呼籲
隨著 AI 技術的不斷進步,重排序算法的類型也越來越多樣化,每種算法都有其獨特的優勢和適用場景。因此,理解各種 ReRank 算法的特點和限制,並根據特定的應用需求進行選擇和調整,是實現高效、高質量 RAG 系統的關鍵。
我們鼓勵讀者深入探索不同的重排序算法,從跨編碼器(Cross-Encoders)、多向量重排序器(Multi-Vector Rerankers)到基於大型語言模型(LLM)的 ReRank 算法等,選擇最適合自己需求的算法。通過對整個 RAG 管道進行全面的觀察和優化,AI 團隊可以構建生產就緒的系統,不僅提升系統的效能,還能確保提供可靠且精確的搜尋結果,滿足日益增長的用戶需求。
結論是,重排序算法在資訊檢索系統的發展中佔有不可替代的位置。隨著技術的不斷發展,它們將繼續在提升搜尋結果質量、解決「幻覺」問題以及優化 RAG 系統運行成本等方面發揮關鍵作用。