
 Yang Abao
Yang Abao- Ai , Finetune , Generative ai
- 9 4 月, 2024
- 413 views
大型語言模型微調新方法 ReFT:從原理到實踐
隨著 AI 技術的飛速發展,語言模型(LLM)在近幾年取得了…

- Yang Abao
- Ai , Generative ai , LLM
- 7 4 月, 2024
- 733 views
Qwen 1.5 MoE:突破大模型的性能瓶頸
引言 在 AI 界的一場沉寂之後,阿里巴巴集團最近發布了一款…
- Yang Abao
- Ai , Generative ai , LLM
- 6 4 月, 2024
- 294 views
Cohere Command R+ AI 模型引領企業級應用新浪潮
在人工智慧(AI)的急速發展下,企業對於更高效、更智慧的語言…
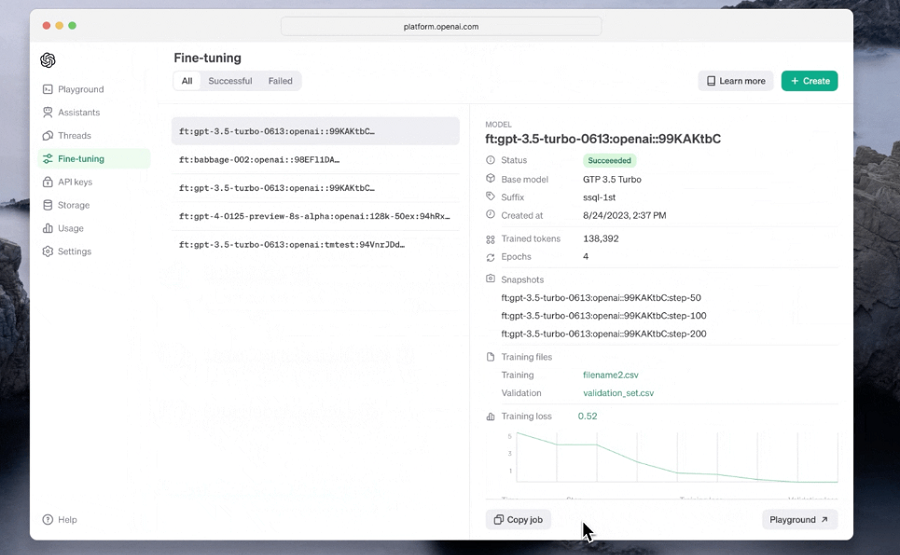
OpenAI 推出新功能,開啟定制化 AI 模型的新篇章
引言 在 AI 領域,OpenAI 一直是創新和突破的代名詞…

- martech_jy
- Finetune , LLM
- 9 3 月, 2024
- 594 views
進階微調 Mistral-7B 模型的方法:直接偏好優化
預訓練的大型語言模型(LLM)只能進行下一個詞預測,使得它們無法回答問題。這就是為什麼這些基礎模型之後需要通過指令和答案的配對進行精調,以充當有用的助手。然而,這個過程仍可能存在缺陷:精調後的 LLM 可能會有偏見、有毒害、有害等。這就是人類反饋中的強化學習(RLHF)發揮作用的地方。
1


Zendesk Resolution Platform: 以 AI 驅動的全新客服解決方案
- martech_jy
- 31 3 月, 2025
- 572 views
2


GPT-4o 原生圖像生成功能:OpenAI 突破性技術與安全框架深度解析
- martech_jy
- 29 3 月, 2025
- 724 views
3


4


5

6
